Generative Model: Autoregressive Model
An autoregressive (AR) model is autoregressive,
$$ \begin{equation} \log p_\theta (x) = \sum_{t=1}^T \log p_\theta ( x_{t} \mid {x_{<t}} ). \end{equation} $$
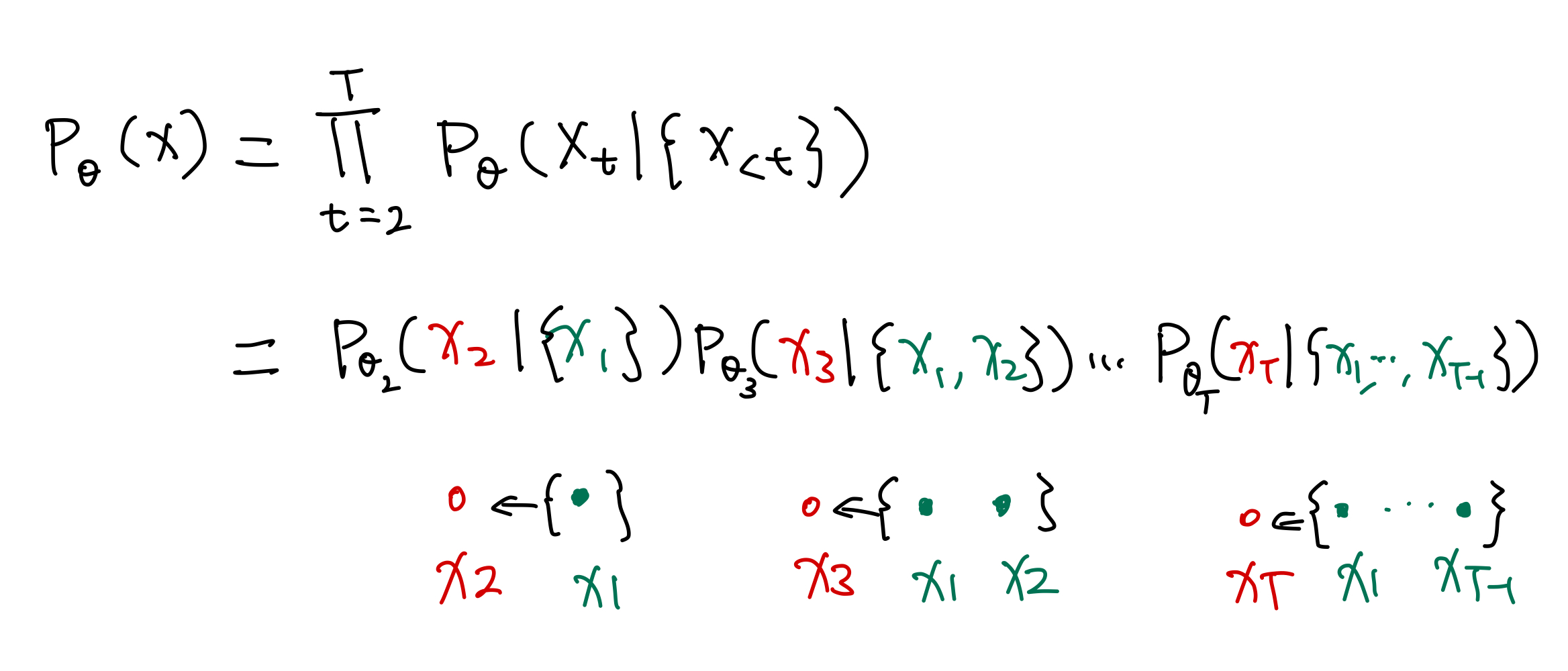
In the above example, the likelihood is modeled as
$$ \begin{align} p_\theta (x) &= \Pi_{t=1}^T p_\theta (x_t \mid x_{1:t-1}) \\ &= p_\theta(x_2 \mid x_{1:1}) p_\theta(x_3 \mid x_{1:2}) \cdots p_\theta(x_T \mid x_{1:T-1}) \end{align} $$
Taking the log of it
$$ \ln p_\theta (x) = \sum_{t=1}^T \ln p_\theta (x_t \mid x_{1:t-1}) $$

Planted:
by L Ma;
References:
- Uria2016 Uria B, Côté M-A, Gregor K, Murray I, Larochelle H. Neural Autoregressive Distribution Estimation. arXiv [cs.LG]. 2016. Available: http://arxiv.org/abs/1605.02226
- Triebe2019 Triebe O, Laptev N, Rajagopal R. AR-Net: A simple Auto-Regressive Neural Network for time-series. arXiv [cs.LG]. 2019. Available: http://arxiv.org/abs/1911.12436
- Ho2019 Ho G. George Ho. In: Eigenfoo [Internet]. 9 Mar 2019 [cited 19 Sep 2021]. Available: https://www.eigenfoo.xyz/deep-autoregressive-models/
- Papamakarios2017 Papamakarios G, Pavlakou T, Murray I. Masked Autoregressive Flow for Density Estimation. arXiv [stat.ML]. 2017. Available: http://arxiv.org/abs/1705.07057
- Germain2015 Germain M, Gregor K, Murray I, Larochelle H. MADE: Masked autoencoder for distribution estimation. 32nd International Conference on Machine Learning, ICML 2015. 2015;2: 881–889. Available: http://arxiv.org/abs/1502.03509
- Liu2020 Liu X, Zhang F, Hou Z, Wang Z, Mian L, Zhang J, et al. Self-supervised Learning: Generative or Contrastive. arXiv [cs.LG]. 2020. Available: http://arxiv.org/abs/2006.08218
- Lippe Lippe P. Tutorial 12: Autoregressive Image Modeling — UvA DL Notebooks v1.1 documentation. In: UvA Deep Learning Tutorials [Internet]. [cited 20 Sep 2021]. Available: https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial12/Autoregressive_Image_Modeling.html
- rogen rogen-george. rogen-george/Deep-Autoregressive-Model. In: GitHub [Internet]. [cited 20 Sep 2021]. Available: https://github.com/rogen-george/Deep-Autoregressive-Model
Similar Articles:
wiki/machine-learning/generative-models/autoregressive-model Links to:L Ma (2021). 'Generative Model: Autoregressive Model', Datumorphism, 08 April. Available at: https://datumorphism.leima.is/wiki/machine-learning/generative-models/autoregressive-model/.