Basic Node Crawler
The original Chinese article is written by ninthakeey. It has been translated and remixed by Datumorphism
Prerequisites
- Nodejs >= 8.9
Overview
A model for a crawler is as follows.
A crawler requests data from the server, while the server responds with some data. Here is a graphic illustration
+----------+ +-----------+
| | HTTP Request | |
| +----------------> |
| Nodejs | | Servers |
| <----------------+ |
| | HTTP Response | |
+----------+ +-----------+
HTTP Requests
API
As for the first step, we need to find which url to request. Chrome and Firefox-based browsers come with the developer’s tool.
In this tutorial, we will be using bilibili.com as an example, which is a video hosting website in China. Bilibili hosts many videos. Along with each video, the status such as the number of viewers of the videos is also displayed. To find out which API we should use, we simply turn on Chrome dev tool, look into the Network tab and find it among the XHR.
screenshot of an example page
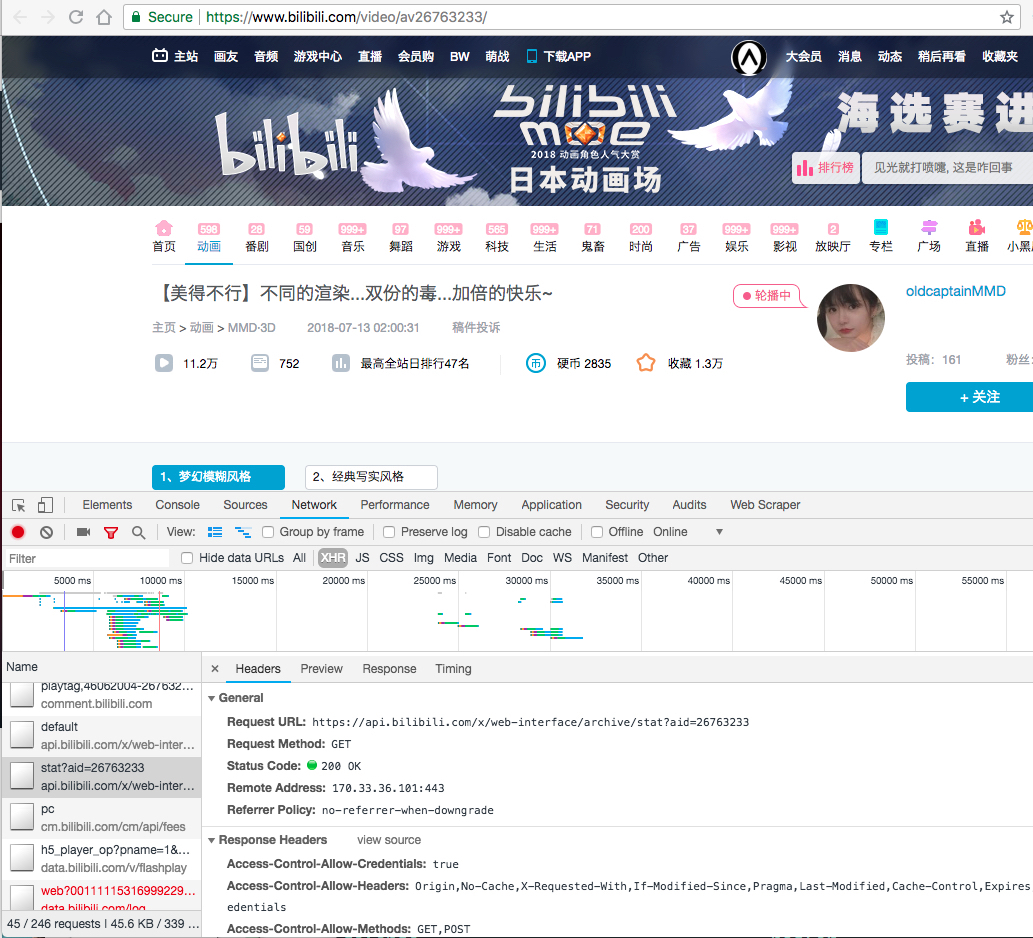
One we obtained the API, we should start coding.
The Code
All we need to do is to request from https://api.bilibili.com/x/web-interface/archive/stat?aid=26763233 and display the data.
We will use the package superagent to send HTTP requests.
superagent
For a first taste of the code, we will run everything on repl.it. Please hit the button on the bottom right corner of the following embed environment to run the code. The code can also be modified as you wish. The results shown in the terminal contains the returned data which is in JSON format as usual.
There is absolute no magic here. The annotated code is provided.
// we use superagent to request from server
const superagent = require('superagent')
superagent
// send GET requests to url
.get('https://api.bilibili.com/x/web-interface/archive/stat')
// here goes the parameters for the request
// we could also use https://api.bilibili.com/x/web-interface/archive/stat?aid=26763233
// as the get url and leave this query function no arguments
// query function will take the dict of parameters
// and append the to the url as ?aid=26763233
.query({ aid:26763233 })
// excute console.log() if the response is successfull
// console.log() prints the results in the terminal
.then(res => res && console.log(res.body))
// catch error and print it in terminal if it fails
.catch(err => console.error(err))Local Manipulation
However, we should not run a production crawler on repl.it. It is the best practice to set up your local programming environment according to the previous article of this series and program on your own computer.
First of all, we create a folder node-simple-spider (or whatever you like) to contain all the files. To install the dependency superagent, we open a terminal and go to this folder. Inside this folder, we type in the terminal
npm i superagent --save
npm and node packages
We create a file with the name index.js in the folder. We copy and paste the following code to the file.
const superagent = require('superagent')
superagent
.get('https://api.bilibili.com/x/web-interface/archive/stat')
.query({aid:26763233})
.then(res => res && console.log(res.body))
.catch(err => console.error(err))To run the code, use
node index.js
in the terminal. The result will be printed in the terminal as follows:
{ code: 0,
message: '0',
ttl: 1,
data:
{ aid: 26763233,
view: 113830,
danmaku: 757,
reply: 260,
favorite: 12947,
coin: 2859,
share: 228,
like: 1833,
now_rank: 0,
his_rank: 47,
no_reprint: 1,
copyright: 1 }
}
Dump Data to File
We can barely do anything with the data if the program only prints it in the terminal. To analyze the data, one simple solution is to save the data in a file.
Node.js comes with a package fs which can be used to save data to a file. The code to achieve this is:
const superagent = require('superagent')
// fs is a standard package that comes with Node.js
const fs = require('fs')
superagent
.get('https://api.bilibili.com/x/web-interface/archive/stat')
.query({ aid:26763233 })
// dump data in a JSON file
.then(res => {
try{
fs.writeFile('data.json', res.text, err => {
console.log('The data is written to data.json!');
});
} catch(err) {
console.error(err)
}
})
.catch(err => console.error(err))We run the code in the terminal. The code will generate a data file data.json in the same folder.
Non-blocking I/O
fs.writeFile() performs the I/O asynchronously. The next line of code runs without waiting for the I/O to finish. This is different from Python. We will explain and explore more asynchronous feature in the future.Useful Links
L Ma (2018). 'Basic Node Crawler', Datumorphism, 07 April. Available at: https://datumorphism.leima.is/wiki/nodecrawler/basic-crawler/.