Machine Learning Overview
What is Machine Learning
Abu-Mostafa, Magdon-Ismail, and Lin summarized machine learning problem using the following chart 1 2. Ultimately, we need to find an approximation $g$ of the true map $f$ from features $\mathcal X$ to targets $\mathcal Y$ on a specific probability distribution of features $P$. This process is done by using an algorithm to select some hypothesis that works.
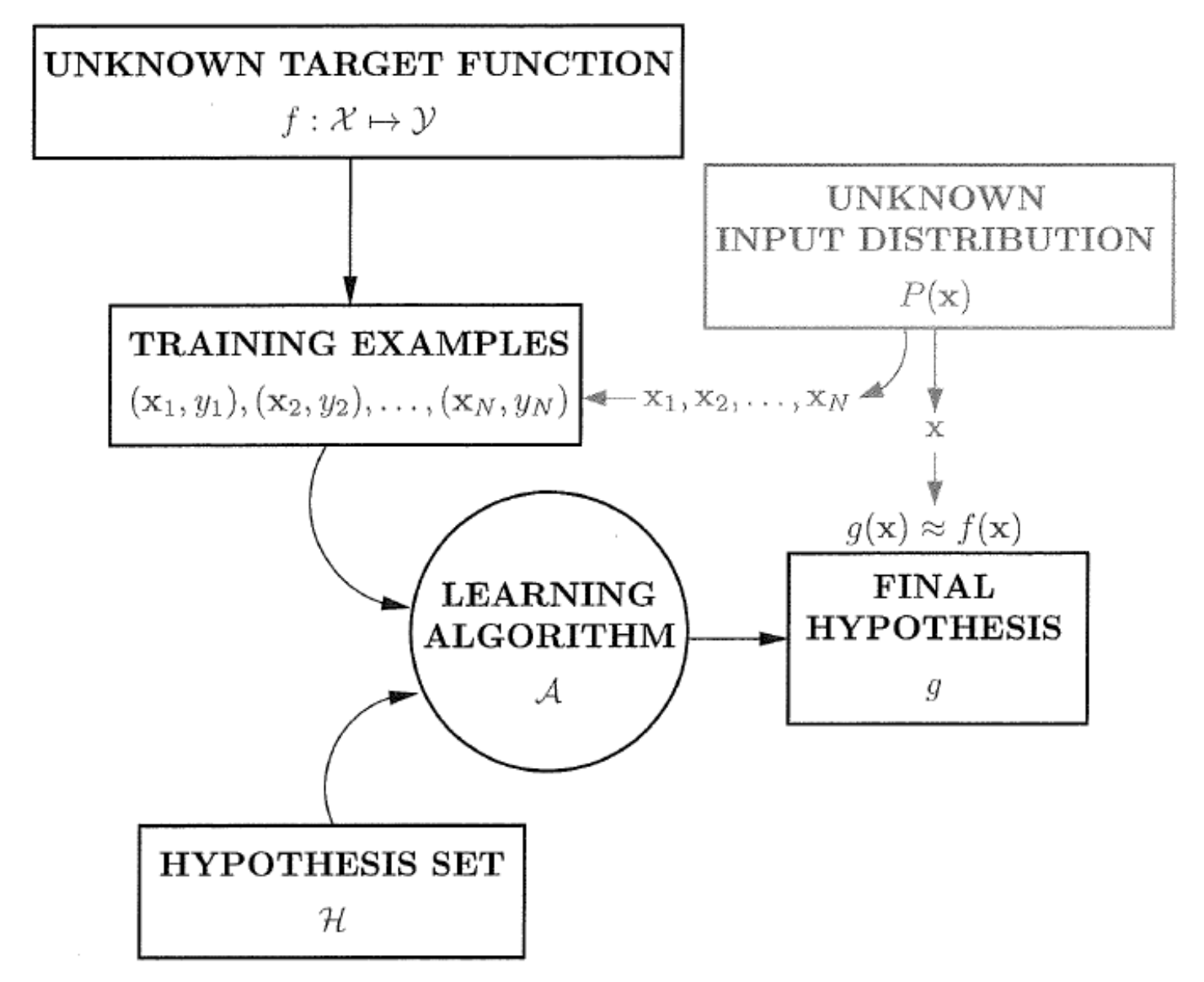
From the book Learning From Data by Abu-Mostafa, Magdon-Ismail, and Lin. I am using a version by Deckert.
In the core of machine learning models, we have three components3:
- Representation: encode data and problem representation, i.e., propose a space to set a stage.
- Evaluation: an objective function to be evaluated that guides the model.
- Optimization: an algorithm to optimize the model so it learns what we want it to do.
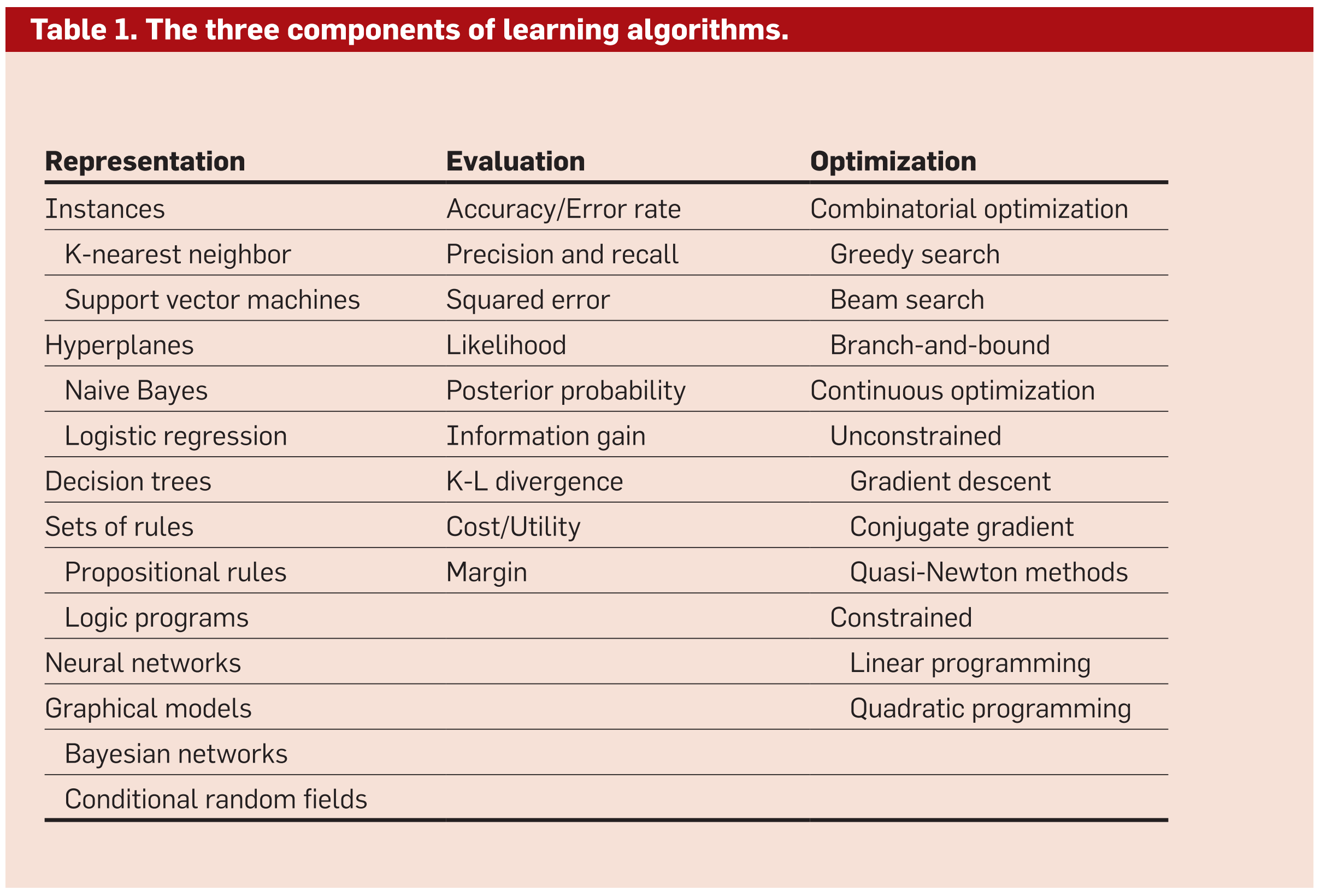
Table from Domingos2012
Machine Learning Workflow
There are many objectives in machine learning. Two of the most applied objectives are classifications and regressions. In classifications and regression, the following four factors are relevant.
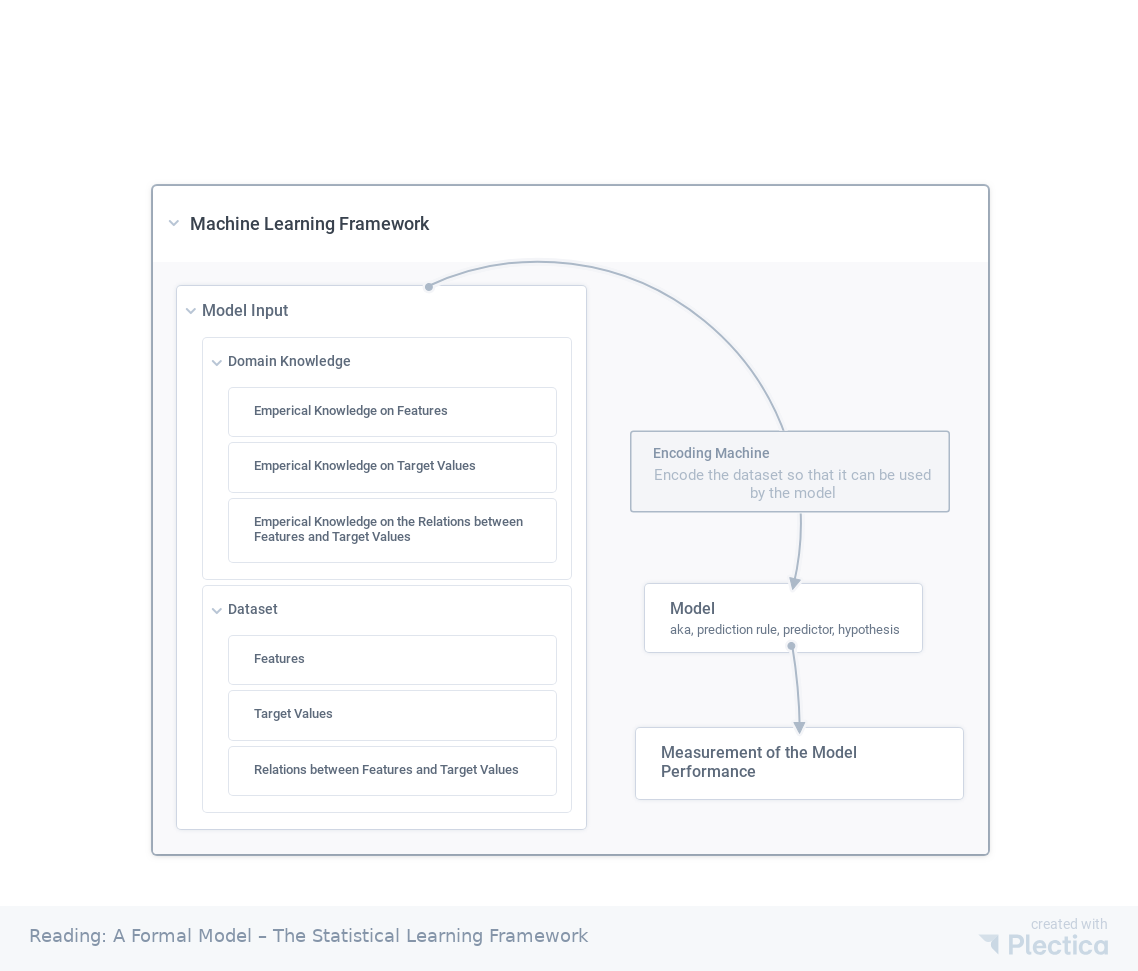
A simple framework of machine learning. The dataset $\tilde{\mathscr D}$ is first encoded by $\mathscr T$, $\mathscr D(\mathbf X, \mathbf Y) = \mathscr T(\tilde{\mathscr D})$. The dataset is feeded into the model, $\bar{\mathbf Y} = f(\mathbf X;\mathbf \theta)$. The model is then tested with the test method, $L_{f, \mathscr D}(h)$. By requiring the test method to satisfy some specific conditions, we solve the model parameters $\mathbf\theta$.
- Input:
- Domain knowledge $\tilde{\mathscr K_D}$.
- on features,
- on target values,
- on relation between features and target values.
- A dataset $\tilde{\mathscr D}(\tilde{\mathbf X}, \tilde{\mathbf Y})$ with $\tilde{\mathbf X}$ being the features and $\tilde{\mathbf Y}$ being the values to be predicted;
- features (domain set): $\tilde{\mathbf X}$,
- target values (label set): $\tilde{\mathbf Y}$.
- relations between features and target values: $f(\mathbf X) \to \mathbf Y$.
- Domain knowledge $\tilde{\mathscr K_D}$.
- A set of “encoders” $\mathscr T_i$ that maps the features $\tilde{\mathbf X}$ into machine-readable new features $\mathbf X$ and predicting values $\tilde{\mathbf y}$ into machine readable new values $\mathbf y$. The dimensions of $\tilde{\mathbf X}$ and $\mathbf X$ may not be the same. In summary, $\mathscr T(\tilde{\mathscr D}) \to \mathscr D$.
- A model (aka, prediction rule, predictor, hypothesis) $h(\mathbf X;\mathbf \theta)\to \bar{\mathbf Y}$ that maps $\mathbf X$ to the values with $\mathbf X$ being a set of input features. $h$ may also be a set of functions.
- A measurement of the model performance, $L_{f, \mathscr D}(h)$.
- Error of model: $L_{f, \mathscr D}(h) = \mathscr L(h(\mathbf X), f(\mathbf X))$, where $\mathscr L$ is distance operator.
Abu-Mostafa2012 Abu-Mostafa, Yaser S and Magdon-Ismail, Malik and Lin, Hsuan-Tien. Learning from Data. 2012. Available: https://www.semanticscholar.org/paper/Learning-From-Data-Abu-Mostafa-Magdon-Ismail/1c0ed9ed3201ef381cc392fc3ca91cae6ecfc698 ↩︎
Deckert2017 Deckert D-A. Advanced Topics in Machine Learning. In: Advanced Topics in Machine Learning [Internet]. Apr 2017 [cited 17 Oct 2021]. Available: https://www.mathematik.uni-muenchen.de/~deckert/teaching/SS17/ATML/ ↩︎
Domingos2012 Domingos, P. (2012). A few useful things to know about machine learning. Communications of the ACM, 55 (10), 78–87. ↩︎
- Mehta, P., Bukov, M., Wang, C. H., Day, A. G. R., Richardson, C., Fisher, C. K., & Schwab, D. J. (2019). A high-bias, low-variance introduction to Machine Learning for physicists. Physics Reports, 810, 1–124.
- Shalev-Shwartz, S., & Ben-David, S. (2013). Understanding machine learning: From theory to algorithms. Understanding Machine Learning: From Theory to Algorithms
- Domingos2012 Domingos, P. (2012). A few useful things to know about machine learning. Communications of the ACM, 55 (10), 78–87.
- Abu-Mostafa2012 Abu-Mostafa, Yaser S and Magdon-Ismail, Malik and Lin, Hsuan-Tien. Learning from Data. 2012. Available: https://www.semanticscholar.org/paper/Learning-From-Data-Abu-Mostafa-Magdon-Ismail/1c0ed9ed3201ef381cc392fc3ca91cae6ecfc698
- Deckert2017 Deckert D-A. Advanced Topics in Machine Learning. In: Advanced Topics in Machine Learning [Internet]. Apr 2017 [cited 17 Oct 2021]. Available: https://www.mathematik.uni-muenchen.de/~deckert/teaching/SS17/ATML/
wiki/machine-learning/overview:wiki/machine-learning/overview Links to:L Ma (2018). 'Machine Learning Overview', Datumorphism, 05 April. Available at: https://datumorphism.leima.is/wiki/machine-learning/overview/.