Contrastive Model: Context-Instance
In contrastive methods, we can manipulate the data to create data entries and infer the changes using a model. These methods are models that “predict relative position”1. Common tricks are
- shuffling image sections like jigsaw, and
- rotate the image.
We can also adjust the model to discriminate the similarities and differences. For example, to generate contrast, we can also use [[Mutual Information]] Mutual Information Mutual information is defined as $$ I(X;Y) = \mathbb E_{p_{XY}} \ln \frac{P_{XY}}{P_X P_Y}. $$ In the case that $X$ and $Y$ are independent variables, we have $P_{XY} = P_X P_Y$, thus $I(X;Y) = 0$. This makes sense as there would be no “mutual” information if the two variables are independent of each other. Entropy and Cross Entropy Mutual information is closely related to entropy. A simple decomposition shows that $$ I(X;Y) = H(X) - H(X\mid Y), $$ which is the reduction of … as the objective. Take two encoded space from the encoder, $g_1$ and $g_2$, we shall maximize the mutual information between the two representations if they are representing the same thing.
Deep InfoMax
However, mutual information is hard to calculate. Models such as [[Deep InfoMax]] Deep Infomax Max Global Mutual Information Why not just use the global mutual information of the input and encoder output as the objective? … maximizing MI between the complete input and the encoder output (i.e.,globalMI) is ofteninsufficient for learning useful representations. – Devon et al[^Devon2018] [[Mutual information]] Mutual Information Mutual information is defined as $$ I(X;Y) = \mathbb E_{p_{XY}} \ln \frac{P_{XY}}{P_X P_Y}. $$ In the case that $X$ and $Y$ are independent variables, … use [[NCE]] Noise Contrastive Estimation: NCE Noise contrastive estimation (NCE) objective function is1 $$ \mathcal L = \mathbb E_{x, x^{+}, x^{-}} \left[ - \ln \frac{ C(x, x^{+})}{ C(x,x^{+}) + C(x,x^{-}) } \right], $$ where $x^{+}$ represents data similar to $x$, $x^{-}$ represents data dissimilar to $x$, $C(\cdot, \cdot)$ is a function to compute the similarities. For example, we can use $$ C(x, x^{+}) = e^{ f(x)^T f(x^{+}) }, $$ so that the objective function becomes $$ \mathcal L = \mathbb E_{x, x^{+}, x^{-}} \left[ - \ln \frac{ e^{ … instead1. For Deep InfoMax, the loss function is
$$ \mathcal L = \mathbb E_{v, x} \left[ -\ln \frac{e^{v^T\cdot s}}{e^{v^T\cdot s} + e^{v^T\cdot s^-}} \right]. $$
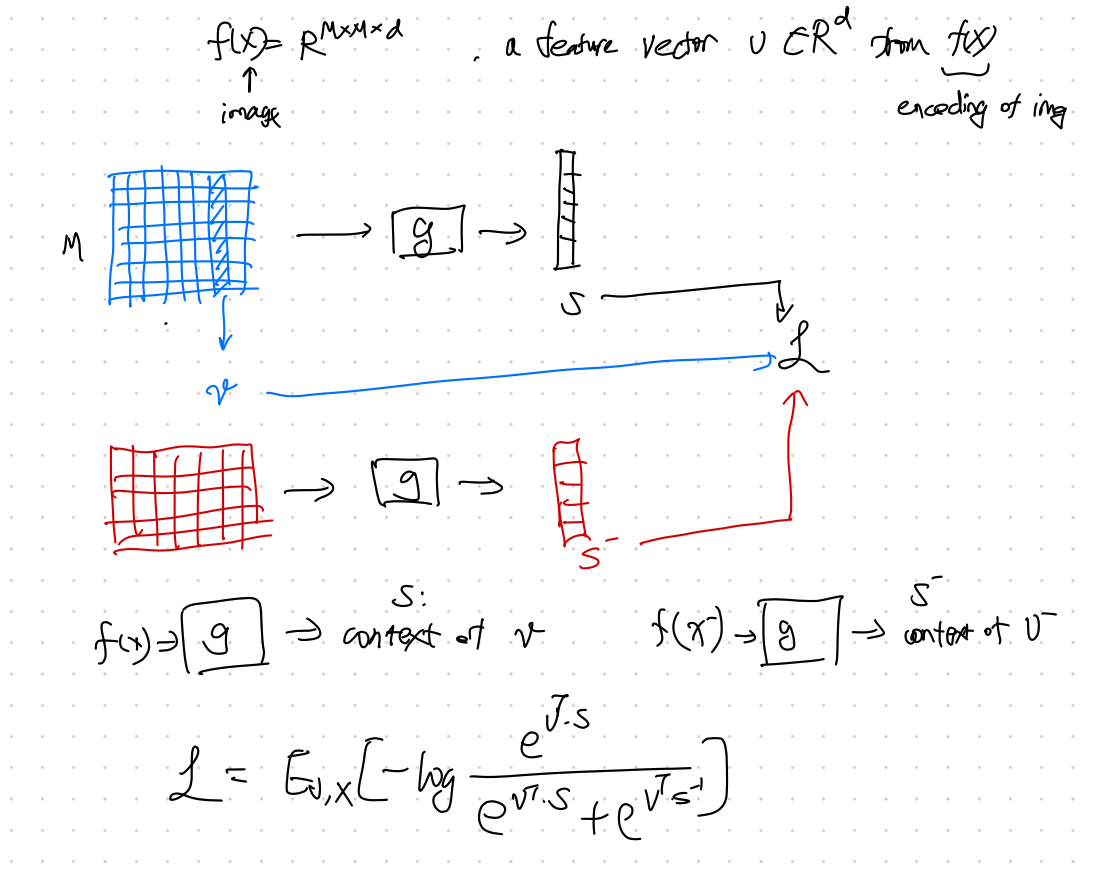
Illustration of Deep InfoMax based on Liu2020.
wiki/machine-learning/contrastive-models/context-instance:wiki/machine-learning/contrastive-models/context-instance Links to:L Ma (2021). 'Contrastive Model: Context-Instance', Datumorphism, 08 April. Available at: https://datumorphism.leima.is/wiki/machine-learning/contrastive-models/context-instance/.