Scale Up
Scaling Up Storage
Scaling Up SQL DB
SAN: Storage Area Network
Use multiple servers on the DB storage to make the query faster.
- Good for Read-only DB
- Not convinient to update DB
Hadoop
Hadoop:
- Distributed storage
- Analysis
4 core modules:
- Hadoop common
- background functionalities
- HDFS
- Divide into blocks
- Distribute
- [[MapReduce]]
Basics of MapReduce
mapreduce
- Old tech
- YARN
- Resource management
The Hadoop Ecosystem:
- Many tools that can be connected to Hadoop or are based on Hadoop
- Not only about the 4 core modules anymore if we consider the ecosystem:
- Spark is also using YARN
- No need to use everything in Hadoop
- Data->(Kafka->Spark)->DB
- The (*) can be using Hadoop
- Data->(Kafka->Spark)->DB
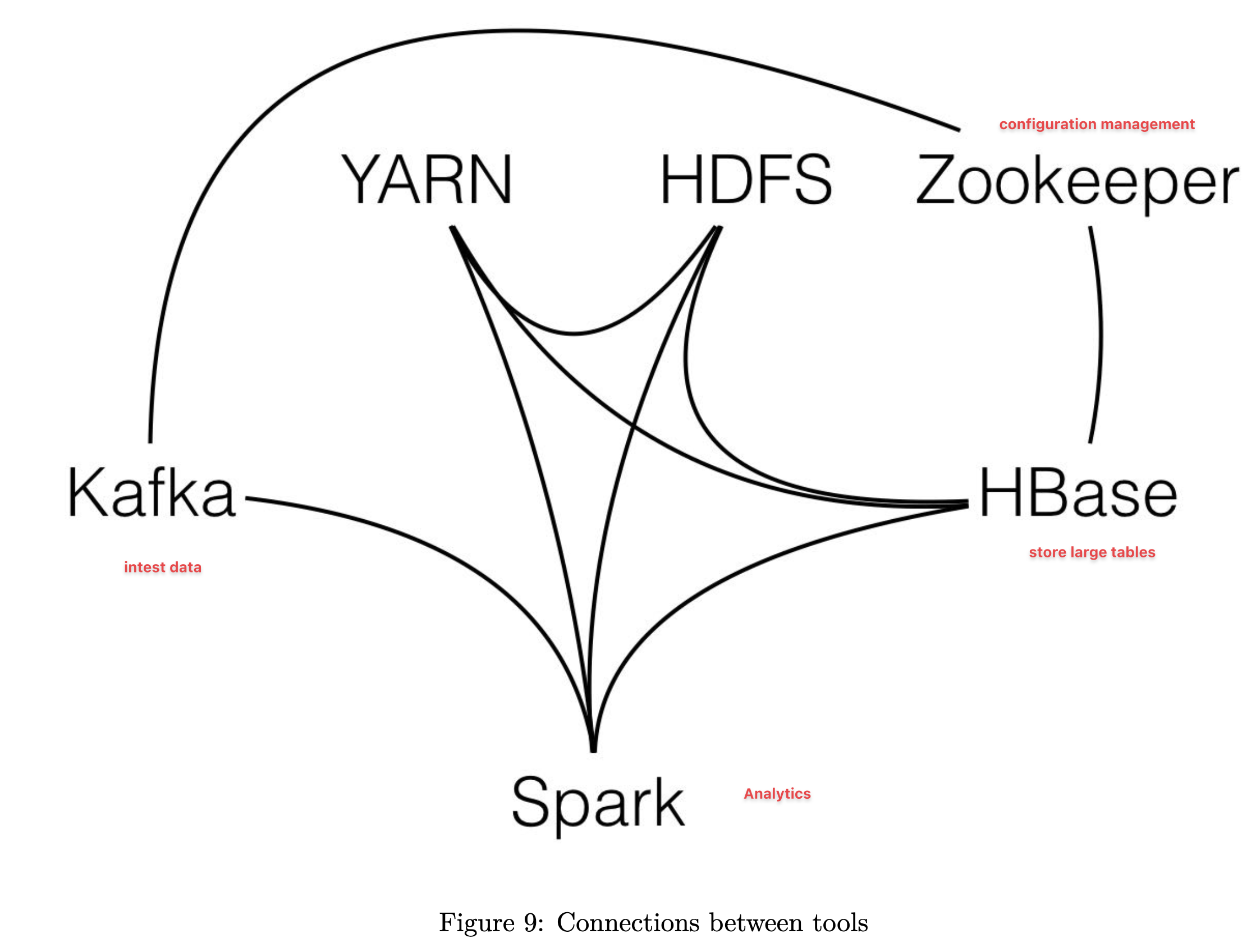
Adapted from https://github.com/andkret/Cookbook
Planted:
by L Ma;
References:
Supplementary:
Dynamic Backlinks to
wiki/data-engeering-for-data-scientist/scale-up: Additional Double Backet Links:
L Ma (2021). 'Scale Up', Datumorphism, 05 April. Available at: https://datumorphism.leima.is/wiki/data-engeering-for-data-scientist/scale-up/.