Data Structure
Dealing with data structure is like dealing with your clothes. Some people randomly drop their clothes somewhere without thinking. But it takes time to retrieve a specific T-shirt. Some people spend more time folding and arranging their clothes. This process makes it easy to find a specific T-shirt. Similar to retrieving clothes, there is always a balance between the computation time (retrieving clothes) and the coding time (folding clothes).
Some Useful Data Structures
This section serves as some kind of flashcard keywords. I am using this section to remind myself of the important concepts.
Binary Tree
- [[Tree]] Data Structure: Tree mind the data structure: here comes the tree ; Binary tree
- Traverse a tree:
- Pre-order traversal: parent->left->right
- In-orer traversal: left->parent->right
- Post-order traversal: left->right->parent
- Level-order traversal: top->bottom, by each level from left to right of the whole tree
Array
Suppose I bought 5 movie tickets for the movie Tenet. Usually, the theater would give out contiguous seats, 0, 1, 2, 3, 4. Your friends are seated as shown in the following table.
| seat | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| people | A | B | C | D | E |

Your friends are seated in the red seats.
Now it is easy to locate a friend. When you find your friend A, just find the third seat next to A to find your friend D.
The seats are like spots in computer memory. Your friends are the values assigned to the spots.
array = [A, B, C, D, E]
becomes an array. This array is accessed with indices, i.e., array[3] is your friend D.
Linked List
What if the theater doesn’t have contiguous seats? You can create a linked list. Friend A only know the spot of friend B, friend B only knows the location of friend C, etc. If you would like to find the seat of friend D, consult A first to find the seat of friend B. Find the seat of friend B then find the seat of friend C. Finally, find friend C to get the seat of friend D.

Your friends are seated in the red seats.
In a linked list, the first element is head and the last element is tail.
Elements can be linked in two different ways, Signly Linked List or Doubly Linked List.
Each node of the singly linked list is assigned two fields, the first field is the value of the node, which stores the information we need, the second field is the link to the next node.

Singly linked list illustration from Wikipedia
Suppose we are solving the Josephus problem. Linked list is good for deletion, however it is computation expensive when it comes to the counting. On the other hand, array structure is good for determining which one to delete, but the deletion involves rearrangement of index the array which requires some computation power.
Stack
Stack is good for adding new items and removing the most recent-added item. (Card on Enki)
Stack data structure is Last in First out, aka LIFO. There are only two ways to change the stack, which are adding an item to the stack and removing the item at the top.
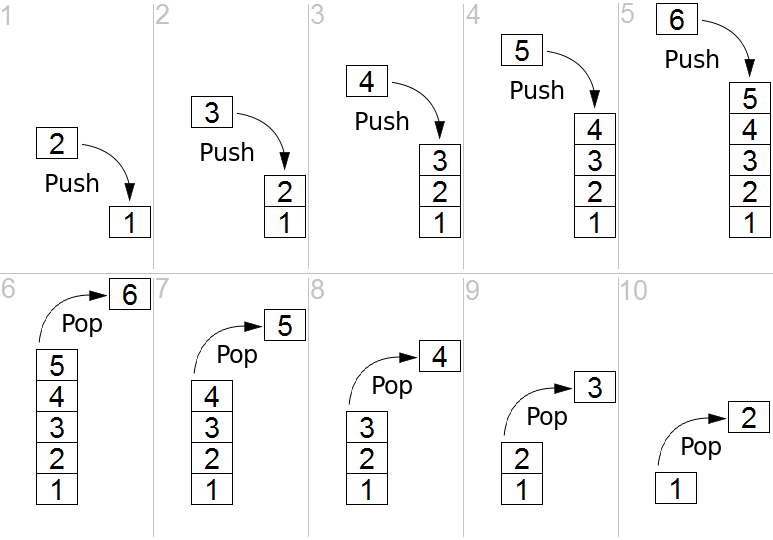
Stack from Wikipedia
Queue
Queue is First in First out, aka FIFO. The name Queue explains itself quite well. In a line of queue, the first one in the line would be the first one served and removed from the queue. To add into the queue, we have to put the new guy at the end of the queue.

Queue from Wikipedia
Graph
wiki/algorithms/data-structure:L Ma (2018). 'Data Structure', Datumorphism, 03 April. Available at: https://datumorphism.leima.is/wiki/algorithms/data-structure/.