Pytorch Data Parallelism
To train large models using PyTorch, we need to go parallel. There are two commonly used strategies123:
- model parallelism,
- data parallelism,
- data-model parallelism.
Model Parallelism
Model parallelism splits the model on different nodes14. We will focus on data parallelism but the key idea is shown in the following illustration.
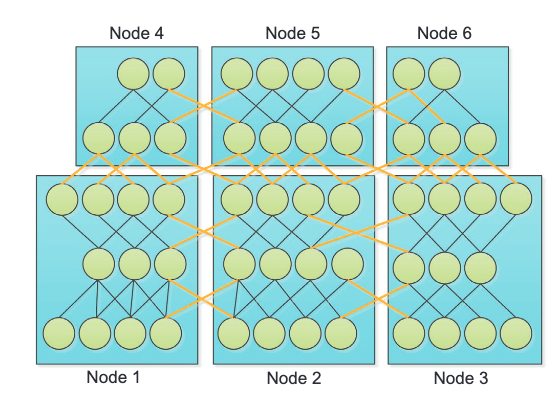
Li X, Zhang G, Li K, Zheng W. Chapter 4 - Deep Learning and Its Parallelization. In: Buyya R, Calheiros RN, Dastjerdi AV, editors. Big Data. Morgan Kaufmann; 2016. pp. 95–118. doi:10.1016/B978-0-12-805394-2.00004-0
Data Parallelism
Data parallelism creates replicas of the model on each device and use different subsets of training data14.
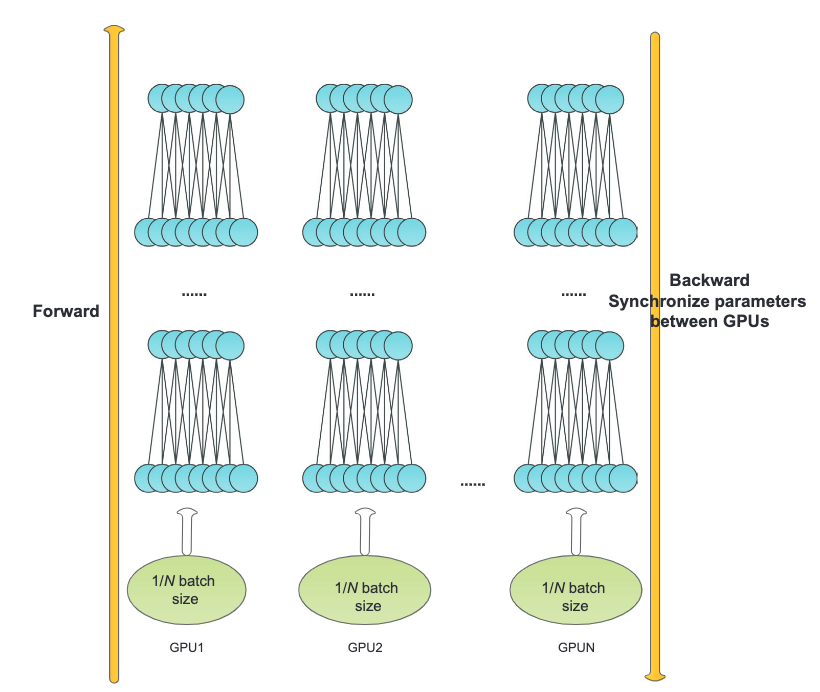
Li X, Zhang G, Li K, Zheng W. Chapter 4 - Deep Learning and Its Parallelization. In: Buyya R, Calheiros RN, Dastjerdi AV, editors. Big Data. Morgan Kaufmann; 2016. pp. 95–118. doi:10.1016/B978-0-12-805394-2.00004-0
Data parallelism is based on the additive property of the loss gradient.
There are two ready to use data parallel paradigms: DataParallel and DistributedDataParallel.
Jargons
To better understand what happens in the strategies, we recommend reading the following.
- CUDA MemoryOptimizing memory operations for CUDA
- The PyTorch documentation provides an illustration on collective communication.
DataParallel in PyTorch
DataParallel is a strategy implemented in PyTorch using multi-threading.
![Mohan A. Distributed data parallel training using Pytorch on AWS. In: Telesens [Internet]. [cited 17 Oct 2022]. Available: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/](../assets/pytorch-data-parallelism/data-parallel-mohan.png)
Mohan A. Distributed data parallel training using Pytorch on AWS. In: Telesens [Internet]. [cited 17 Oct 2022]. Available: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
The above illustration shows that the master GPU, “GPU 0”, is the coordinator and also computes more than others. This creates imbalance in GPU usage.
Due to multi-threading, DataParallel also suffers from GIL5.
DistributedDataParallel in PyTorch
DistributedDataParallel (DDP) is a strategy implemented in PyTorch using
[[multi-processing]]
The Python Language: Multi-Processing
Python as a programming language
. DDP is the recommended method in the PyTorch documentation.
![Mohan A. Distributed data parallel training using Pytorch on AWS. In: Telesens [Internet]. [cited 17 Oct 2022]. Available: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/](../assets/pytorch-data-parallelism/distributed-data-parallel-mohan.png)
Mohan A. Distributed data parallel training using Pytorch on AWS. In: Telesens [Internet]. [cited 17 Oct 2022]. Available: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
Jia2018 Jia Z, Zaharia M, Aiken A. Beyond Data and Model Parallelism for Deep Neural Networks. arXiv [cs.DC]. 2018. Available: http://arxiv.org/abs/1807.05358 ↩︎ ↩︎ ↩︎
Xiandong2017 Xiandong. Intro Distributed Deep Learning. In: Xiandong [Internet]. 13 May 2017 [cited 19 Oct 2022]. Available: https://xiandong79.github.io/Intro-Distributed-Deep-Learning ↩︎
Mao2019 Mao L. Data Parallelism VS Model Parallelism in Distributed Deep Learning Training. In: Lei Mao’s Log Book [Internet]. 23 May 2019 [cited 19 Oct 2022]. Available: https://leimao.github.io/blog/Data-Parallelism-vs-Model-Paralelism/ ↩︎
Li2016 Li X, Zhang G, Li K, Zheng W. Chapter 4 - Deep Learning and Its Parallelization. In: Buyya R, Calheiros RN, Dastjerdi AV, editors. Big Data. Morgan Kaufmann; 2016. pp. 95–118. doi:10.1016/B978-0-12-805394-2.00004-0 ↩︎ ↩︎
pytorch-ddp-tutorial Getting Started with Distributed Data Parallel — PyTorch Tutorials 1.12.1+cu102 documentation. In: PyTorch [Internet]. [cited 19 Oct 2022]. Available: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html ↩︎
- Wolf2020 Wolf T. 💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups. HuggingFace. 2 Sep 2020. Available: https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255. Accessed 19 Oct 2022.
- Mao2019 Mao L. Data Parallelism VS Model Parallelism in Distributed Deep Learning Training. In: Lei Mao’s Log Book [Internet]. 23 May 2019 [cited 19 Oct 2022]. Available: https://leimao.github.io/blog/Data-Parallelism-vs-Model-Paralelism/
- pytorch-lightning-tricks Effective Training Techniques — PyTorch Lightning 1.7.7 documentation. In: PyTorch Lightning [Internet]. [cited 19 Oct 2022]. Available: https://pytorch-lightning.readthedocs.io/en/stable/advanced/training_tricks.html#accumulate-gradients
- Jia2018 Jia Z, Zaharia M, Aiken A. Beyond Data and Model Parallelism for Deep Neural Networks. arXiv [cs.DC]. 2018. Available: http://arxiv.org/abs/1807.05358
- Li2016 Li X, Zhang G, Li K, Zheng W. Chapter 4 - Deep Learning and Its Parallelization. In: Buyya R, Calheiros RN, Dastjerdi AV, editors. Big Data. Morgan Kaufmann; 2016. pp. 95–118. doi:10.1016/B978-0-12-805394-2.00004-0
- Xiandong2017 Xiandong. Intro Distributed Deep Learning. In: Xiandong [Internet]. 13 May 2017 [cited 19 Oct 2022]. Available: https://xiandong79.github.io/Intro-Distributed-Deep-Learning
- Mohan2019 Mohan A. Distributed data parallel training using Pytorch on AWS. In: Telesens [Internet]. [cited 17 Oct 2022]. Available: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
- pytorch-dist_tuto Writing Distributed Applications with PyTorch — PyTorch Tutorials 1.12.1+cu102 documentation. In: PyTorch [Internet]. [cited 19 Oct 2022]. Available: https://pytorch.org/tutorials/intermediate/dist_tuto.html#collective-communication
- pytorch-ddp-tutorial Getting Started with Distributed Data Parallel — PyTorch Tutorials 1.12.1+cu102 documentation. In: PyTorch [Internet]. [cited 19 Oct 2022]. Available: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
cards/machine-learning/practice/pytorch-data-parallelism Links to:L Ma (2022). 'Pytorch Data Parallelism', Datumorphism, 10 April. Available at: https://datumorphism.leima.is/cards/machine-learning/practice/pytorch-data-parallelism/.