Learning Rate
Finding a suitable learning rate for our model training is crucial.
A safe but time wasting option is to use search on a grid of parameters. However, there are smarter moves.
Smarter Method
A smarter method is to start with small learning rate and increase it on each mini-batch, then observe the loss vs learning rate (mini-batch in this case). The learning rate that leads to the greatest gradient decline is a suitable learning rate 1 2 3.
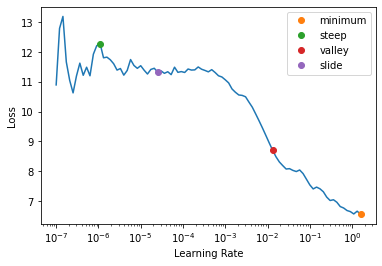
Figure taken from fastai docs
The code for this method can be found on the GitHub repo of fastai.
See Also
Pointer2019 Pointer I. Programming PyTorch for deep learning: Creating and deploying deep learning applications. Sebastopol, CA: O’Reilly Media; 2019. ↩︎
Howard&Gugger2020 Howard J, Gugger S. Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD. O’Reilly Media, Incorporated; 2020. Available: https://www.oreilly.com/library/view/deep-learning-for/9781492045519/ ↩︎
fastaidocs Howard J, Thomas R. Hyperparam schedule. In: fastai [Internet]. [cited 30 Nov 2021]. Available: https://docs.fast.ai/callback.schedule.html#Learner.lr_find ↩︎
- Pointer2019 Pointer I. Programming PyTorch for deep learning: Creating and deploying deep learning applications. Sebastopol, CA: O’Reilly Media; 2019.
- fastaidocs Howard J, Thomas R. Hyperparam schedule. In: fastai [Internet]. [cited 30 Nov 2021]. Available: https://docs.fast.ai/callback.schedule.html#Learner.lr_find
- Howard&Gugger2020 Howard J, Gugger S. Deep Learning for Coders with Fastai and PyTorch: AI Applications Without a PhD. O’Reilly Media, Incorporated; 2020. Available: https://www.oreilly.com/library/view/deep-learning-for/9781492045519/
cards/machine-learning/practice/learning-rate:cards/machine-learning/practice/learning-rate Links to:L Ma (2021). 'Learning Rate', Datumorphism, 11 April. Available at: https://datumorphism.leima.is/cards/machine-learning/practice/learning-rate/.