Curriculum
Prerequisites
Programming
- Bash:
- Python:
- [[The Python Language]] The Python Language Python as a programming language
- [[all posts with the python tag]] Python
- C++:
- [[C/C++]] C/C++
- [[all posts with the C++ tag]] C++
alternatives:
- R
- Matlab
Python
Some essential libraries:
- Data
- numpy
- scipy
- pandas
- [[Articles with pandas tag]] pandas
- dask
- [[PySpark]] Data Processing - (Py)Spark Processing Data using (Py)Spark
- Visualization
- matplotlib
- [[Articles with matplotlib tag]] Matplotlib
- seaborn
- plotly
- matplotlib
- and your machine learning libraries
Use virtual environments:
- virtualenv
- conda
- [[Articles with Anaconda tag]] Anaconda
Use notebooks
- Jupyter
- [[Articles with Jupyter tag]] Jupyter
Computer Science
These theories make people think faster. They don’t pose direct limits on what data scientists can do but they will definitely give data scientists a boost.
- [[Basics of Computation]] Basics of Computation Essential knowledge of computations
- [[Data Structure]]
Data Structure
mind the data structure
- [[Data Structure: Tree]] Data Structure: Tree mind the data structure: here comes the tree
- [[Data Structure: Graph]] Data Structure: Graph mind the data structure: here comes the graph
- Algorithms
- Complexity
- HackerRank
Math
Some basic understanding of these is absolutely required. Higher levels of these topics will also be listed in details.
- Statistics
- [[Statistics Concepts]] Statistics Knowledge snippets about statistics
- [[Statistical Methods]] Statistics Basics of statistics
- Linear Algebra
- [[Linear Algebra]] Linear Algebra
- Calculus
- Differential Equations
- [[Differential Equation]] Differential Equation
Engineering for Data Scientist
I use the book by Adreas Kretz as a checklist 1.
[[Data Engineering for Data Scientists: Checklist]] Data Engineering for Data Scientists: Checklist A checklist to get a shallow understanding of the basics and the ecosystemData Storage and Retrieval
- Database Basics
- [[Basics of Database]] Basics of Database Essential knowledge of database
- Data Files
- [[Data File Formats]] Data File Formats Data storage is diverse. For data on smaller scales, we are mostly dealing with some data files. work_with_data_files Efficiencies and Compressions Parquet Parquet is fast. But Don’t use json or list of json as columns. Convert them to strings or binary objects if it is really needed.
- Query Language
- SQL
- [[Basics of SQL]] Basics of SQL Essential knowledge of programming
- [[SQL tag]] SQL
- PGSQL
- [[PGSQL tag]] PGSQL
- SQL
- Regular Expression
- [[Regular Expression Basics]] Regular Expression Basics Some quick start material on regular expression.
- Scraping
- [[Node Crawler]] Node Crawler Write a crawler using nodejs
- [[Articles tagged Web Scraping]] Web Scraping
Statistics
Descriptive statistics
It is crucial for the interpretations in statistics.
- Probability theory
- random variable
- probability distribution
- pmf
- [[articles tagged with distributions]] Distributions
- Bayes
- Summary statistics
- location
- variation
- correlation
- [[Covariance Matrix]] Covariance Matrix Also known as the second central moment is a measurement of the spread.
- [[Explained Variation]] Explained Variation Using [[Fraser information]] Fraser Information The Fraser information is $$ I_F(\theta) = \int g(X) \ln f(X;\theta) , \mathrm d X. $$ When comparing two models, $\theta_0$ and $\theta_1$, the information gain is $$ \propto (F(\theta_1) - F(\theta_0)). $$ The Fraser information is closed related to [[Fisher information]] Fisher Information Fisher information measures the second moment of the model sensitivity with respect to the parameters. , Shannon information, and [[Kullback information]] KL …
- [[Correlation Coefficient and Covariance for Numeric Data]] Correlation Coefficient and Covariance for Numeric Data Detecting correlations using correlations for numeric data
- Laws
- Law of large numbers
- Central limit theorem
- Law of total variance
- much more
- Probability Estimation
- Kernel density estimation
Inferential statistics
To get closer to the ultimate question about causality
- Parameter Estimation
- Maximum Likelihood: [[Likelihood]] Likelihood Likelihood is not necessarily a pdf
- Hypothesis Testing
- [[Statistical Hypothesis Testing]] Statistical Hypothesis Testing Hypothesis testing in statistics
- Inference
- Bayesian inference
- Confidence interval
- [[Articles with tagged with Bayesian]] Bayesian
- Frequentist inference
- Bayesian inference
EDA
Data wrangling and exploratory data analysis.
Understand the Source of the data
- Know the source
- Understand the data collection procedure
- Understand the limitation of the data
Dimensionality and Numerosity Reduction
Reduce the dimension of the data:
- PCA
- [[Unsupervised Learning: PCA]] Unsupervised Learning: PCA Principal component analysis is a method to remove redundancies of the features by looking into the variances.
- SparsePCA
- ICA
Numerosity reduction:
- Parametric
- Using model parameters to represent the data
- Non-parametric
- Histograms
- Clustering
- Resampling
Data Normalization
Normalization is very important in many models.
Normalization of raw data:
- [[Normalization Methods for Numeric Data]] Normalization Methods for Numeric Data Detecting correlations using correlations for numerical data
Normalization in neural networks:
- Batch normalization
Missing Data
Data imputation
Unbiased Estimators
Binning
- Bin the sparse values
- Bin continuous data if necessary
Outlier Detection
Anomaly Detection
Noisy Data
Sampling and Resampling
Feature Selection
Baseline Model
Association Rules
Visualization
What to show
- Relationship
- Composition
- Compose to compare
- Compose to calculate (the total)
- Compose to form a distribution
Types of Charts
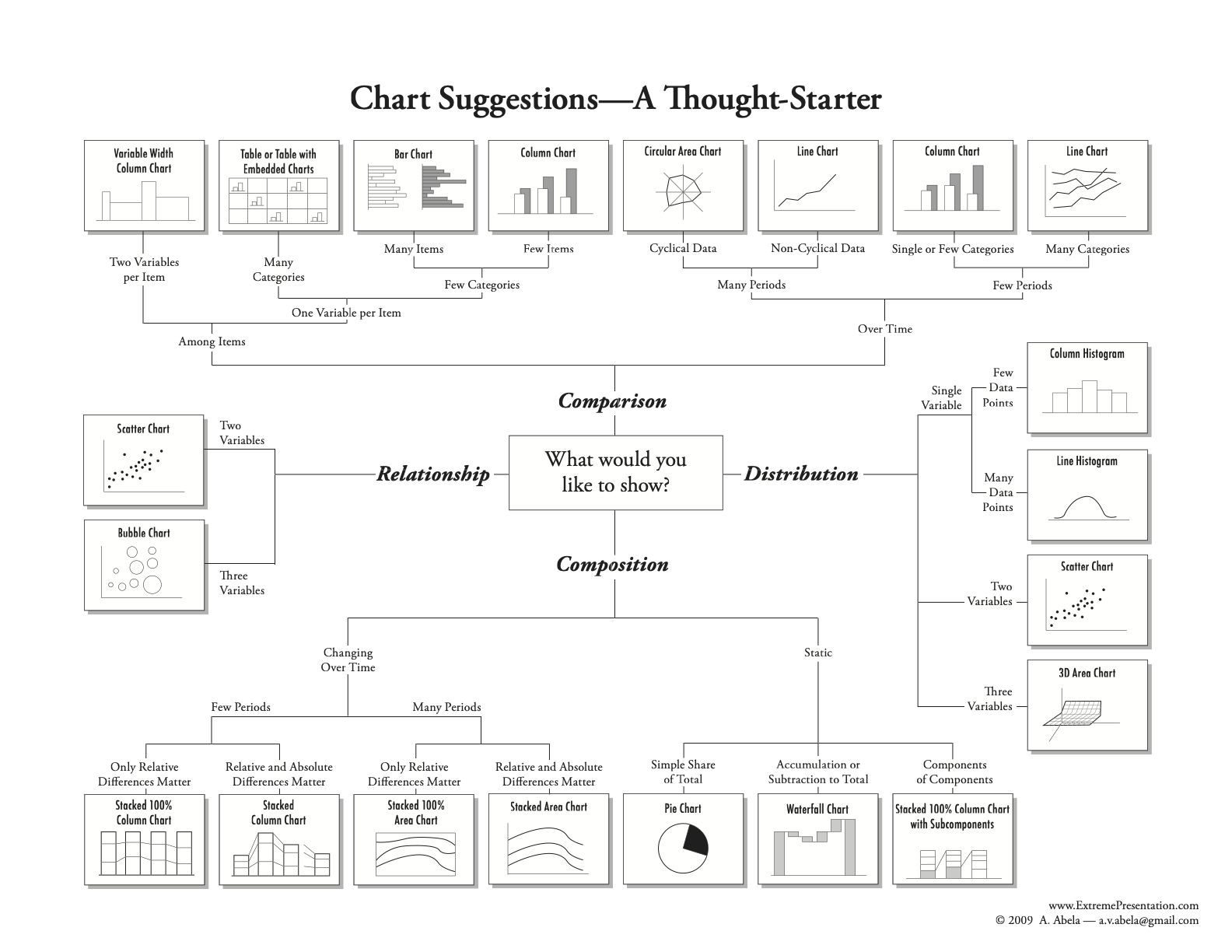
Know your charts. Source: Chart Suggestions — A Thought-Starter
Other useful references:
- Chart choosing. In: Chart.Guide [Internet]. 20 Feb 2019 [cited 30 Nov 2021]. Available: https://chart.guide/charts/chart-choosing/
- Visual Vocabulary. [cited 30 Nov 2021]. Available: http://ft-interactive.github.io/visual-vocabulary/
- Financial-Times. chart-doctor/Visual-vocabulary.pdf at main · Financial-Times/chart-doctor. In: GitHub [Internet]. [cited 30 Nov 2021]. Available: https://github.com/Financial-Times/chart-doctor
- Holtz Y, Healy C. From data to Viz. In: Find the graphic you need [Internet]. [cited 30 Nov 2021]. Available: https://www.data-to-viz.com/
Grammar of Graphics
- [[Graph Creation]] Graph Creation Stages Three stages of making a graph: Specification Assembly Display Specification Statistical graphic specifications are expressed in six statements DATA: a set of data operations that create variables from datasets TRANS: variable transformations (e.g., rank) SCALE: scale transformations (e.g., log) COORD: a coordinate system (e.g., polar) ELEMENT: graphs (e.g., points) and their aesthetic attributes (e.g., color) GUIDE: one or more guides (axes, legends, etc.) Assembly Assembling a scene …
- [[The Grammar of Graphics]] The Grammar of Graphics Reading notes for the book The Grammar of Graphics
Tools
- Python
- matplotlib
- [[articles tagged with matplotlib]] Matplotlib
- seaborn
- plotnine
- plotly
- matplotlib
- Dashboarding
- streamlit
- plotly dash
Machine Learning
Concepts
- Features
- Estimators
- Risk
- [[ERM: Empirical Risk Minimization]] ERM: Empirical Risk Minimization In a [[learning problem]] The Learning Problem The learning problem proposed by Vapnik:1 Given a sample: $\{z_i\}$ in the probability space $Z$; Assuming a probability measure on the probability space $Z$; Assuming a set of functions $Q(z, \alpha)$ (e.g. loss functions), where $\alpha$ is a set of parameters; A risk functional to be minimized by tunning “the handles” $\alpha$, $R(\alpha)$. The risk functional is $$ R(\alpha) = \int Q(z, \alpha) \,\mathrm d F(z). $$ A learning problem …
- [[SRM: Structural Risk Minimization]] SRM: Structural Risk Minimization [[ERM]] ERM: Empirical Risk Minimization In a [[learning problem]] The Learning Problem The learning problem proposed by Vapnik:1 Given a sample: $\{z_i\}$ in the probability space $Z$; Assuming a probability measure on the probability space $Z$; Assuming a set of functions $Q(z, \alpha)$ (e.g. loss functions), where $\alpha$ is a set of parameters; A risk functional to be minimized by tunning “the handles” $\alpha$, $R(\alpha)$. The risk functional is $$ R(\alpha) = \int Q(z, …
- [[Cross Validation]] Cross Validation Cross validation is a method to estimate the [[risk]] The Learning Problem The learning problem proposed by Vapnik:1 Given a sample: $\{z_i\}$ in the probability space $Z$; Assuming a probability measure on the probability space $Z$; Assuming a set of functions $Q(z, \alpha)$ (e.g. loss functions), where $\alpha$ is a set of parameters; A risk functional to be minimized by tunning “the handles” $\alpha$, $R(\alpha)$. The risk functional is $$ R(\alpha) = \int Q(z, \alpha) \,\mathrm d …
- Bias and Variance
- Overfitting, Underfitting
- [[Goodness-of-fit]] Goodness-of-fit Does the data agree with the model? Calculate the distance between data and model predictions. Apply Bayesian methods such as likelihood estimation: likelihood of observing the data if we assume the model; the results will be a set of fitting parameters. … Why don’t we always use goodness-of-fit as a measure of the goodness of a model? We may experience overfitting. The model may not be intuitive. This is why we would like to balance it with parsimony using some measures of …
- Loss
- Huber Loss
- Performance
- Regression
- R^2
- Classification
- F score
- Precision
- Recall
- Regression
Frameworks
Supervised
Regression
- Linear Regression
- [[Linear Methods]] Linear Methods linear methods
- Polynomial Regression
- Generalized Linear Model
- Poisson Regression: for counts
- [[Poisson Regression]] Poisson Regression Poisson regression is a generalized linear model for count data. To model a dataset that is generated from a [[Poisson distribution]] Poisson Process , we only need to model the mean $\mu$ as it is the only parameters. The simplest model we can have for some given features $X$ is a linear model. However, for count data, the effects of the predictors are often multiplicative. The next simplest model we can have is $$ \mu = \exp\left(\beta X\right). $$ The $\exp$ makes sure that the mean is …
- Poisson Regression: for counts
Classification
- Logistic Regression
- [[Logistic Regression]] Logistic Regression logistics regression is a simple model for classification
- SVM
- [[Unsupervised Learning: SVM]] Unsupervised Learning: SVM unsupervised learning: support vector machine
- Tree
- [[Decision Tree]] Decision Tree In this article, we will explain how decision trees work and build a tree by hand. The code used in this article can be found in this repo. Definition of the problem We will decide whether one should go to work today. In this demo project, we consider the following features. feature possible values health 0: feeling bad, 1: feeling good weather 0: bad weather, 1: good weather holiday 1: holiday, 0: not holiday For more compact notations, we use the abstract notation $\{0,1\}^3$ to describe a set …
- Naive Bayes
- [[Naive Bayes]] Naive Bayes Naive Bayes
- kNN
- Gaussian Mixture
Unsupervised
Semi-supervised
Reinforcement Learning
Graphs and Networks
Neural Networks
L Ma (0001). 'Curriculum', Datumorphism, 01 April. Available at: https://datumorphism.leima.is/awesome/curriculum/.
Table of Contents
References:
Supplementary:
Current Note ID:
- awesome/curriculum/index.md
Links to: